Here's a qualm I've had for a little while with argument order: in a lot of cases, it's fairly arbitrary. For example, consider the following small chunk of code.
Block block = world.getBlockAt(10, 0, 7);
JOptionPane.showConfirmDialog(null,
"Obliterate the " + block + "?",
"Message",
JOptionPane.INFORMATION_MESSAGE,
JOptionPane.YES_NO_OPTION);
In the first line, we get a block from some world. The argument order here actually makes quite a bit
of sense. We can intuitively assume that the 10 is the x-coordinate, the 0 is the y-coordinate, and
the 7 is the z-coordinate, since pretty much any sane programmer will write coordinates as (X, Y, Z).
The second is a bit fuzzier. The first argument is a null, which carries a whole different
set of problems which I'm sure I'll discuss in the future. The second and third are parts of the message.
It makes a certain amount of sense to have the message text come first, as it's arguably more important
than the message title. Then the final two arguments are the option type and the message type. Now,
when I run this code (with a dummy block value, of course), I see the following message pop up.
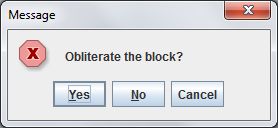
Hm... that's quite odd. Clearly, I told it to show me an information message with a "Yes" and a "No" option, but this looks like an error message with a "Yes", "No", and "Cancel" option. The keen Java coder might have already noticed my mistake. I transposed the final two arguments; the option type is supposed to come before the message type. And this illustrates the issue that I'm bringing up. The argument order is arbitrary here (there's no theoretical or practical reason that one should come before the other), and I slipped up and put the arguments in the wrong order. The type system didn't catch it, the compiler didn't catch it, the runtime didn't catch it, and more than likely most of the people reading this page didn't catch it.
Now, a solution to this problem has existed for quite a while now. It's called named parameters, a concept that originated a long time ago in the land of Lisp and has since propogated to several more modern languages including Python, Ruby (since 2.0), C# (since 2010), and Scala. So let's break down how good the support is in these languages for named arguments. Specifically, we'll be looking at how early errors are caught.
We'll start with the dynamic languages. Ruby has fairly recent (since 2013, I believe) support for named arguments. Arguments that are intended to be referenced by name must be declared so, creating a distinction between "positional" and "named" arguments.
def speak(speaker, sound:, volume: 10.0)
...
end
This defines a method speak which takes a positional argument, followed by two named
arguments. The first is required and the second has a default value. It could be called as follows.
speak(cow, sound: "Moo")
speak(loudCow, sound: "Moo", volume: 100.0)
speak(backwardCow, volume: 3.0, sound: "Moo")
speak(confusedCow, volume: 1.0) # This line will cause a runtime error
A couple of things of interest here. The first example shows that the volume: argument
is not required. The second and third examples show that the argument order becomes irrelevant with
named arguments. That is, since the arguments are associated with their name rather than their position,
the order you pass them in no longer matters. Finally, the fourth argument shows that named arguments
can still be made to be required by leaving a trailing colon in the definition. Pretty much any possible
confusion about arguments will be caught and made into a runtime error, rather than slipping through
like that JOptionPane error earlier.
Python's named argument support is fairly similar to Ruby's, with a bit of a different syntax.
def speak(speaker, *, sound, volume = 10.0):
...
The asterisk in the middle separates the named arguments from the positional arguments. Other than
that, the semantic support is fairly similar, with the one added benefit that Python, unlike Ruby,
will allow you to refer to even the positional arguments by name. So we could feasibly call
speak as follows.
speak(speaker = namedCow, sound = "Moo")
The equivalent line of Ruby code would fail.
Now, with dynamic languages like Ruby and Python, the best we can really hope for is a runtime error. So let's move on to the static languages. C# and Scala both have fairly basic support for named arguments. That is, the caller of a method can choose to call it with named arguments, but there is no way to force the caller to do so.
def speak(speaker: Animal, sound: String, volume: Double = 10.0): Unit = {
...
}
speak(speaker = scalaFlavoredCow, sound = "Moo") // This works
speak(scalaFlavoredCow, "Moo") // But so does this
This is a nice improvement over only allowing positional arguments, but it's still not optimal. It would be nice if library writers could declare certain arguments as named so that they cannot be called positionally. Sure, in our speaking cow example, it's fairly obvious what each argument does, and since each argument has a distinct type the type system should catch any glaring problems with argument order. So let's make a more difficult function.
def drawHealth(width: Double, height: Double, healthPerLine: Double): Unit = {
...
}
There, that's a bit trickier. We have some healthbar object in a computer game, and it's draw method take width and height arguments, as well as an argument specifying how much health to draw per line. Now, a careful Scala coder might go ahead and call this with named arguments to ensure that everything goes smoothly, but if some other coder comes along later and is in a hurry, he or she might use the positional form. Since it's obvious that the argument order here could be easily confused, we would like a way to force the user to think about the argument order to avoid little mistakes like that.
To this end, I'm going to leap over to Haskell now. We'll go back to Scala and adapt the same ideas
there in a minute, but the fact is that the solution I'm going to present is actually almost trivial
in Haskell. Now, Haskell has zero support for named arguments at all, but it does have something really
nice: newtypes. No, I didn't forget a space there; the keyword to create one is newtype.
newtype Index = Index Int
This defines a new type called Index which contains an integer and nothing else. Values
within this type can be created using the named Index and extracted using
pattern matching (we could have used a longer form syntax which defines an accessor function for
extraction, but there are many cases where that's overkill). Fairly boring so far, but the neat
thing here is that when a type is declared with newtype (as opposed to the more
powerful data keyword), it will be completely stripped away at compile time. That means
that while the type checker will treat Index as a distinct type, the compiler will strip
away that extra layer, removing any runtime overhead associated with packing and unpacking this type.
So we have a way to define new types which carry no runtime overhead. How can we use that to solve our
argument order problem?
drawHealth :: Double -> Double -> Double -> IO ()
drawHealth width height healthPerLine = ...
-- To call:
drawHealth 200 200 100
This is our drawHealth method from Scala, translated into a Haskell function. Now let's
try using a newtype to eliminate some of these argument ambiguities.
newtype PerLine = PerLine Double
drawHealth :: Double -> Double -> PerLine -> IO ()
drawHealth width height (PerLine healthPerLine) = ...
-- To call:
drawHealth 200 200 (PerLine 100)
A couple of things to note here. First off, when calling the function, we actually had to acknowledge
that we knew the third argument was the "health per line" argument. Had we messed up and tried to
pass it in as the first argument, a type error would have been triggered, since PerLine
and Double are in fact distinct types. Second, the pattern matching in the
drawHealth implementation immediately extracts the actual Double value
out of the newtype so we don't have to worry about accessing it.
What we've gained here is some security at the type level against user mistakes when passing in arguments. And all it cost us was one additional line of code at the top; there's no runtime overhead and access into the newtype is trivial. Now, let's look back at Scala. In Scala, we can get very close to the benefits of newtypes, including the lack of runtime overhead. So let's start by defining a new class in Scala, similar to the newtype we defined in Haskell.
class PerLine(val value: Double)
def drawHealth(width: Double, height: Double, healthPerLine: PerLine): Unit = {
...
}
// To call:
drawHealth(200, 200, new PerLine(100))
Ehhh... that's not too pretty. It's quite clear we're constructing an object here, and PerLine
makes very little sense as an object in a traditional OOP sense. Fortunately, Scala has a way of hiding
this fact. In Scala, you can declare a class to be a "case class", which changes a few of the rules so
that the class behaves more like a functional data type.
case class PerLine(value: Double)
def drawHealth(width: Double, height: Double, healthPerLine: PerLine): Unit = {
...
}
// To call:
drawHealth(200, 200, PerLine(100))
Okay... better. We don't have that "new" declaration reminding us that we're using an object allocation to do this. But internally, this is still basically the same thing. However, the Scala developers clearly knew their Haskell, because Scala 2.10 introduced the idea of value classes, which are very close to newtypes. A value class has a single immutable datatype within it and can be compiled away (except in certain special circumstances) into the underlying type so that the JVM doesn't have to allocate an object.
case class PerLine(value: Double) extends AnyVal
def drawHealth(width: Double, height: Double, healthPerLine: PerLine): Unit = {
...
}
// To call:
drawHealth(200, 200, PerLine(100))
There. Now we have no runtime overhead when we construct that PerLine instance. The only
downside is that we'll still have to refer to our underlying Double as
healthPerLine.value. There's no easy way around this. We could try to cleverly place an
implicit conversion somewhere inside the method so that we can pretend it's a Double, but
the easiest solution is also the simplest one.
case class PerLine(value: Double) extends AnyVal
def drawHealth(width: Double, height: Double, _healthPerLine: PerLine): Unit = {
val PerLine(healthPerLine) = _healthPerLine
...
}
One extra line, and now we don't have to worry about the wrapper class inside the method.
Now, you can get a similar effect in C++ with little to no runtime overhead using a minimal struct. In Java and C#, you're going to have a harder time since everything tends to be thrown onto the heap. My point is this, though. Type systems are powerful things. You can convince your type system to check your argument order and a lot of other things. Too many programmers who come from C or C# or Java underestimate the power of a proper type system like that of Haskell or Scala (C++ also has a very powerful type system in this sense, but it's also unwieldy at times). So use your types to document your values, and you'll be amazed at how self-documenting they can be.
[back to blog index]